- Neurocean用户编程接口通过OOP(面向对象)的方式进行提供,具有很好的聚集性,便于学习及使用;
- 通用接口均采用具名函数和动态绑定,抛弃传统的虚函数设计机制,暴露对象均为代理对象,具有极高的二进制兼容性;
- 提供了包括模型构建及编译、运行监控及可视化、运行会话管理、模型序列化及反序列化在内的接口支持。
1. 变量体系
1.1 数据类型支持
变量支持丰富的数据基础类型,包括:
- 64位浮点数
- 64位无符号整数
- 64位有符号整数
- 32为浮点数
- 32位无符号整数
- 32位有符号整数
- 16位浮点数
- 16位无符号整数
- 16位有符号整数
- 8位无符号整数
- 8位有符号整数
- 单变量还支持字符串
1.2 变量的基础信息
Variable 提供了变量体系相关的接口,变量包括名称、描述、是否共享、是否持久化、布局等相关属性的设置或获取接口。变量的具体类型通过变量布局指定,布局指变量的具体类型及布局,可以分为两类:
- 一类标定是单变量;
- 一类是张量,是指张量按照何种顺序存储内部元素,张量更进一步可以分为时间空间布局、NCHW布局及NHWC布局等。
Variable可以进一步区分为SingleVariable(单变量)及TensorVariable(张量变量)。
1.3 单变量
SingleVariable是单变量,存储和持有单个数值或字符串。
- VariableValue 包括数据类型及具体数据的存储,数据存储类型指定了变量的具体类型,所有的变量类型以union结构体共享同一个位置的存储空间;
- 提供了完备的对象构建、数据设置及获取及字符串解析数值等相关的接口支持。
1.4 张量变量
TensorVariable的数据承载主体是Tensor,即张量: - 张量包括维度信息、张量形状、数据类型、Filler(填充器); - 获取张量变量数据内容 - 加载或保存数据到CSV文件;
Tensor作为存储的载体,包括了数据类型、数据布局、单元素的字节大小、张量的形状等相关信息; - 提供了丰富的内存分配型及数据引用型Tensor的构建方法; - 提供了 create_like、fill、empty、total方括号索引等功能的支持;
Filler(张量填充器)统一了张量变量的初始化机制,提供了一种异步填充机制,可以用于初始化或重置张量的内容,主要提供了如下Filler: - 常量填充, 使用一个固定值填充张量 - 拷贝填充, 使用等效的Tensor进行填充 - 均匀随机填充, 指定数据范围随机均匀填充 - 正态随机填充, 指定均值及方差进行正态随机填充 - 局部卷积填充, 通过指定连接位置范围进行对应位置的均匀填充 - 填充器可以按需扩展,灵活方便
2. 模型组织
2.1 类脑建模
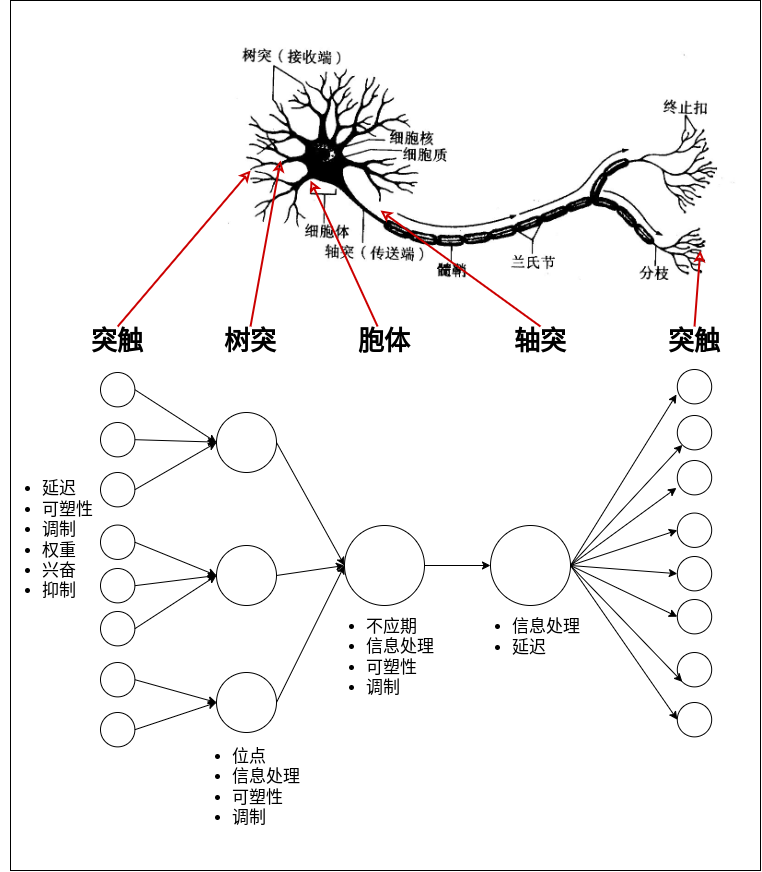
从神经元的形态结构及功能特点来看,类脑建模需要满足的一些基本特性,从信息传递及处理来看,神经元之间通过突触进行相互连接, 先通过突触从其它神经元获取输入;突触处理后传递到树突,再经由树突处理后传递到神经元胞体;电流的不断流入导致细胞内电位不断积累, 当超过某一阈值时,产生动作电位;动作电位经轴突进一步转递到末端的突触,最终传递给下游的神经元。
- 突触是神经元接受输入的主要途径,也是将信息进行输出的主要途径,突触具有延迟、可塑性、调制、信息处理、兴奋性或抑制性等特点;
- 树突接收突触的输入,进行处理后进一步传递给胞体,不同位置的树突在功能上有一定的差异,同时也具有可塑性及调制等相关的特性;
- 胞体是神经元进行信息处理的核心部位,是动作电位的来源,具有较强的信息处理能力,具有不应性、可塑性及调制等特性;
- 轴突将处理的信息进一步传递到末端的突触,进一步传递给其它神经元,轴突也具有一定的信息处理能力及延迟等特性;
2.1.2.人工神经网络建模
一般而言,在进行人工建模时,神经元及突触是必不可少的,例如:在ANN中,通过将神经元抽象为简单的信息状态再加上简单的信息处理, 如RELU,Sigmoid等激活类操作;而突触则抽象为简单的权重表达,如Fully Connected操作,相互之间连接的权重则被抽象为权重进行表示, 同样Convolution操作也有类似的性质,在现代DNN建模中,通常将操作进行了融合,如在Convolution中融合偏置及激活等操作, 但是从信息处理的角度来看还是一致的。
上述建模方式其结构相对比较简单,动态特性及时间特性的表达能力较弱,同时对生物神经机制的借鉴也非常有限, 无法很好地表达生物神经系统的机制,不能满足类脑建模的需求;为满足更多的建模需求,借鉴更多的生物神经机制, 在神经元建模时通常采用脉冲神经元作为基础模型,在此之上构建更复杂的网络结构。
当前的脉冲网络建模中,重点几乎都集中在脉冲神经元的细节描述,而针对更高级的拓扑结构和神经机制却缺乏有效的范例。 同时针对脉冲神经元的建模也缺乏统一的规范,没有成熟的模型规范及成熟的模型案例,处于各抒己见,自成一家的情况。 针对建模粒度、拓扑描述、学习机制等的情况则更加复杂,在完整性、灵活性及扩展性上都缺少有效的规范及参考案例。
2.1.3.类脑建模的完备性、灵活性及扩展性
Neurocean提出了一种包括神经元基础模型(包括其细节描述),拓扑结构、模块组织、高级机制(如可塑性、调制) 及扩展机制在内的类脑统一建模的规范体系,同时满足类脑建模的完备性、灵活性及扩展性。下面分别针对类脑建模的完备性、 灵活性及扩展性进行介绍
完备性
- 模型能力描述完备性
模型静态特征描述完备性,依据变量体系的完备性来保证,动力学特征的描述完备性,可以通过独立编程建模来保证;
- 模型结构划分完备性
在建模时,将神经系统按照合理的结构划分后能够完整地表述生物的神经系统建模需求,即划分的结构能完整组合成各种类脑模型,同时满足各部分的细节建模需求。
- 模型拓扑连接的完备性
在拓扑结构上的完备性,是指能够完整地描述类脑建模中的各种拓扑结构,灵活地描述各种复杂的拓扑结构。
- 模块组织的完备性
模块组织的完备性主要指能够灵活地描述类脑建模的各种组织模式,满足类脑建模在不同层次的建模需求,例如从大脑、脑区、核团等不同层次的模型组织。
灵活性
- 模型扩展的灵活性
模型扩展的灵活性是指系统增加新的模型结构和模型实例的灵活性,能否具有灵活增加新的结构或模型的能力。
- 拓扑结构的灵活性
模型组织的灵活性是指模型在组合上的灵活性,比如系统即支持突触到神经元的连接,也支持突触->树突->神经元的连接、支持拓扑的动态调整、支持环路等。
- 模块组织的灵活性
模块的灵活性主要表现在模型能够灵活组织,即可满足模块的无限嵌套,也可满足模块的复用,同时还具有良好的封装及抽象能力,满足多层次类脑建模的需求。
扩展性
- 模型描述的扩展性
模型描述的扩展性体现在模型的描述能力可以按需进行扩展,如基础数据类型的扩展,模型动力学描述方式的扩展等。
- 模型结构的扩展性
针对模型结构的划分,可以进行更细节的拆分或者新的结构添加,并且在拆分或添加后能进行完整的组合及兼容。
- 模型实例的扩展性
针对某一类具体的模型结构,可以按需进行扩展,比如增加新的神经元模型或突触模型。
- 拓扑结构的扩展性
拓扑结构的扩展性,体现在连接模式的建立和绑定具有良好的扩展能力,可以满足特异的拓扑结构或拓扑类型的描述。
- 模块组织的扩展性
模块组织的扩展性是指模型的组织可以快速进行封装及并扩展形成具有特定功能的组织模块,因此不是固定不变的,在结构上及功能上都具有良好的扩展能力。
2.1.4.模型结构的划分
神经元主要包括突触、树突、胞体、轴突等基础结构,为了更好地满足建模的需求,本文也相应地在建模上初步划分为突触、树突、 及胞体等结构。其中胞体是神经元的主要动力学部件,也是脉冲生成的位置,为了增强神经元的表达能力及模型组合的灵活性, 在胞体的前增加了胞体前部件(如不应性机制机构),在胞体后加入了胞体后部件(如轴突机制结构)。 针对突触及突触可塑性的灵活性,同时二者又是强关联,故将突触及突触可塑性进行分离建模,保证了二者独立性, 实现组合上的灵活性及各自模型的简洁性。由于引入了树突模型,为满足信息的回流,我们针对树突模块提供相关连的映射转换部件, 实现信息的反向回流。
整体上将神经元模型划分为突触、突触可塑性、树突、映射转换、胞体前部件、胞体、胞体后部件等结构。参考神经元的形态结构进行比较, 在主要结构划分上是完整的,能够完整地描述神经元的形态结构,而针对各部分的细节描述,则可由各部分的独立建模来完成; 因此,上诉的模型结构划分在结构上是相对完备的。
2.1.5.模型组织的基础单元
在生物神经系统中,神经元的组织具有很强的聚集性及层次化结构,并且同层次的神经元往往具有相近的形态结构和功能 (如视网膜的神经元细胞分层),在人工神经网络中也可以借鉴相似的机制,将特性相近,功能相似的神经元以组的形式进行组织, 这将带来诸多好处,首先其与生物神经系统的组织机制接近,具有良好的仿生特性,其次将相近特性的神经元进行批量管理, 方便进行统一的建模、监测及优化。
在进行模型结构的划分时,其也是以神经元作为基础进行的。所以被拆分的子部件依然具有相似的特性,在功能及结构上高度相似, 可以分别以群组的方式进行管理,其在组织结构上是等效的。为保证组织结构的有效性及合理性,故群组建模必须满足平等性、 无关性及等效性,主要表现在如下几个方面:
群组仅仅是一个管理单位,将相似的操作或元素进行统一管理,内部元素相互之间不存在直接逻辑联系,但是具有相近的基础属性或特征, 因此内部元素之间彼此是平等的,没有主次关系,相互之间无直接关联;
元素间不进行直接通信,通过统一机制进行通信(可以是统一内存分配,也可以是消息通信机制);
同群组元素按排列顺序被再次划分为不同的小组时,和原组具有等效性,即群组可被拆分为更小的群组进行具体调度执行;
2.2 端口机制
在DNN建模的中,主要是以模块层次化堆叠来组建更加复杂的模型,单个模块或模型支持输入及输出,一个模块可以接收0个或多个输入, 产生一个及以上的输出,如FulllyConnection, Convolution, Pool等都是接收一个输入产生一个输出, 而Concat则是接收多个输入产生一个输出。而针对模块间的拓扑结构的描述,则是使用边来进行描述, 指定某一模块的输出连接到另一个模块的输出,这样就能形成复杂的计算图。
上诉拓扑连接的模式上仍然存在诸多缺陷:
首先,在DNN中是不支持环状连接的,这是DNN的信息传递、学习方式及计算模式所决定的,目前主流的DNN框架都是采用这种模式。 由于不支持环状拓扑,因此在描述复杂拓扑结构时将会受到极大的限制,因为在生物神经系统中存在大量的环状连接拓扑, 如反馈抑制、前馈抑制及相互抑制等基础环路都是环状拓扑的;
其次,上诉拓扑连接方式只支持简单的信息传递,不支持更加复杂的连接描述,针对连接拓扑的描述能力相对较弱,同时也缺乏有效的扩展机制;
最后,由于类脑计算和传统的DNN计算范式存在较大差异,DNN采用从前向后的计算范式或从后相前的计算范式,模块间存在严格的数据依赖, 因此计算的局部性较低,只有当拓扑结构中存在多个并行线路时才具有一定的并行性,否则操作之间是有严格的计算顺序的; 反观类脑计算,类脑计算的计算是以神经元为核心,局部性良好,虽然存在复杂的拓扑结构,但是并不强调严格的信息依赖, 因为脉冲神经元对于数据依赖的影响具有有良好的过滤作用,其在时间效应上的积累能有效消除数据依赖带来的延迟影响, 因此类脑神经网络具有高度的并行性,其计算范式和DNN的计算范式是完全不同的。
基于上诉缺陷,必须设计一种全新的机制来满足类脑计算在拓扑描述及计算模式上的建模需求。为支持复杂的模块连接拓扑, Neurocean抽象出了端口机制,端口表述了模块与其它模块的拓扑联系,引入端口机制,增加了拓扑结构的描述能力及扩展能力, 通过端口将拓扑关系进行统一建模,支持端口模式的扩展则保证了拓扑结构的扩展能力。
2.2.1 端口(Port)
端口是模块端口机制的基础,是其它端口的基础,端口提供了端口名称及端口类型等获取功能
2.2.2 Model端口
Input,输入端口是Model的输入,接受外部模块的输入
Output,输出端口是Model的输出,产生输出,可以连接到其它输出端口
Reference,引用端口提供给Model一种引用其它Model变量的机制,双方具有严格的绑定关系
Connection, 连接端口是一种模型管理接口,绑定到连接模型
2.2.3 AbstractModule 端口
ProxyInput, 代理输入端口是AbstractModule的输入端口, 可以连接到内部模块,也可以接受其它端口的连接;
ProxyOutput, 代理输入端口是AbstractModule的输出端口, 可以接受连接到内部模块,也可以连接其它外部端口;
2.3 组织基础
Neurocean以Node作为模型组织的基础,是所有的模型的基类, 统一了建模并提供了对名称、描述等信息的管理。
2.4 基础模型
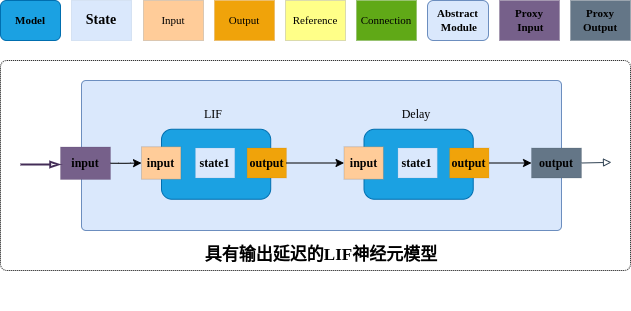
Model为模型组织的基本单元, Model是一个基础类,是所有模型的基础, 其简要示意图如下:
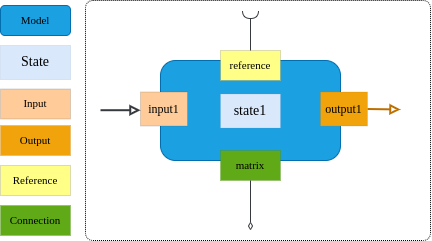
上图简要地描述了基础模块的组成要素,主要是从模型组织及使用的角度来进行描述的,其特点概括如下:
基础模块包括端口、状态及其代表的实际的动态过程,接受输入后产生输出到下游;
端口可以分为输入端口(Input)、输出端(Output)、引用端口(Reference)及连接端口(Connection)等;
状态表述了模型的特性,是模型的特征,可以是变量值、字符串及张量等具体形态;
输入及输出的关系一般是固定的对应关系,即在给出模型的构建参数后,其对应关系被确定了,不需要额外指定;
提供了操作管理、可以实现基础模块的动态注册、统一构建即管理的功能;
提供了参数管理、便捷地查询参数,更新参数;
提供了端口管理,快速访问端口,方便快捷地构建拓扑结构;
常见案例:神经元,全连接突触,卷积连接突触、一般性过程等;
基础模型进一步被扩展为如下几类:
2.4.1 ConnectModel
连接模型是针对输入及输出间存在随机或任意连接关系的模型基础类;
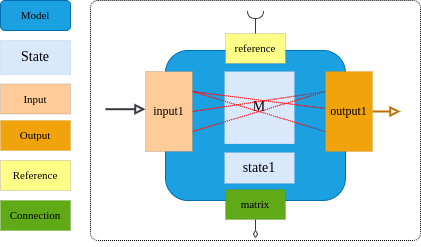
- 输入及输出间存在的是复杂的对应关系,存在大量的随机性及不确定性;
- 例如:上游神经元组和下游神经元组的不确定突触连接,突触到树突的连接等;
2.4.2 NeuronGroup
神经元组是神经元的基础容器, 容纳了一群性质相近的神经元
Note: 一组神经元组最大支持65535个神经元
2.4.3 SynapseGroup
突触组是突触的基础容器,容纳一群特性相近的突触;
突触组继承至连接模型, 描述的是突触的输入及输出存在不规则连接,提供了一系列的接口用于指定突触连接关系;
- 一对一连接;
- 指定概率的全连接;
- 指定一批神经元到一个神经元;
- 指定一个神经元到一批神经元;
- 指定一批神经元到一批神经元;
- 指定连接索引矩阵
- 侧向抑制连接,一般输入和输出同源,且输入输出数目相等,除自身位置外,其它连接关系均存在
2.4.4 DendriteGroup
树突组是树突的基础容器,容纳一群特性相近的树突
Note: 树突建模不考虑一对多的情形,即只存在多对一的连接,模型本身提供了限制, 已经指定了输出的输入,二次指定不再有效,除非全部清理后再建立。
树突组继承至连接模型, 描述的是树突的输入及输出存在不规则连接,提供了一系列的接口用于指定突触连接关系;
- 一对一连接;
- 指定概率的连接;
- 指定一批神经元到一个神经元;
- 指定连接索引矩阵
2.4.5. 基础模型的延伸
- 二元操作, add/max/min/sub...
- 单元操作, abs/sin/cos...
- 选择器,如多路通路选择,条件选择等
- 合并操作,如concat
- Reshape
- Permute
- 池化
- 其它DNN操作
- DNN的无缝衔接
2.5 AbstractModule
抽象模块,抽象模块为模型的组织提供灵活的管理及扩展能力
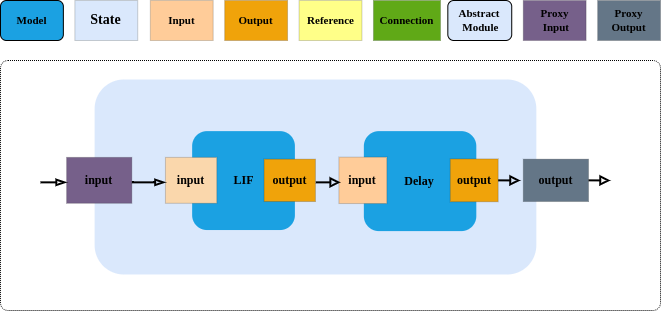
是一种抽象容器,可以容纳基础模型或其它模块;
本身作为一个模块被应用,实现模块的多层级嵌套组织;
提供端口管理的功能,可以创建端口,查询端口;
提供了基础模型构建功能,构建成功后直接加入模块中;
提供了抽象模块的构建功能,构建后直接加入模块中;
可以将内部的输入输出添加代理端口进行封装;
需要运行的基础模型由内部及外部的关联性确定,淡化了网络的概念;
2.6 经典基础回路
2.6.1 神经元-突触-神经元-突触可塑性
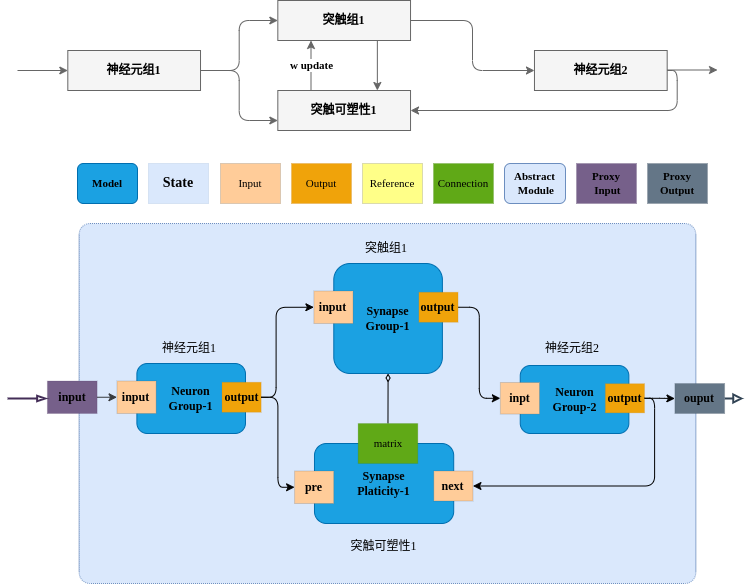
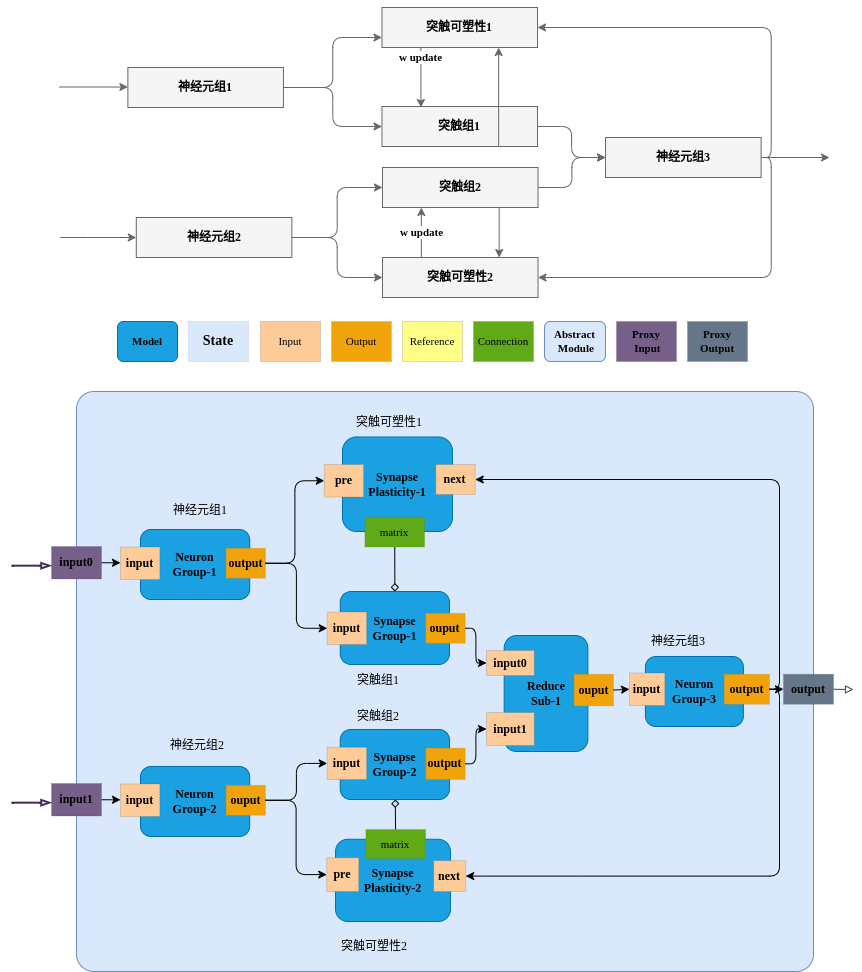
2.6.2 神经元-突触-神经元-突触可塑性多路合并
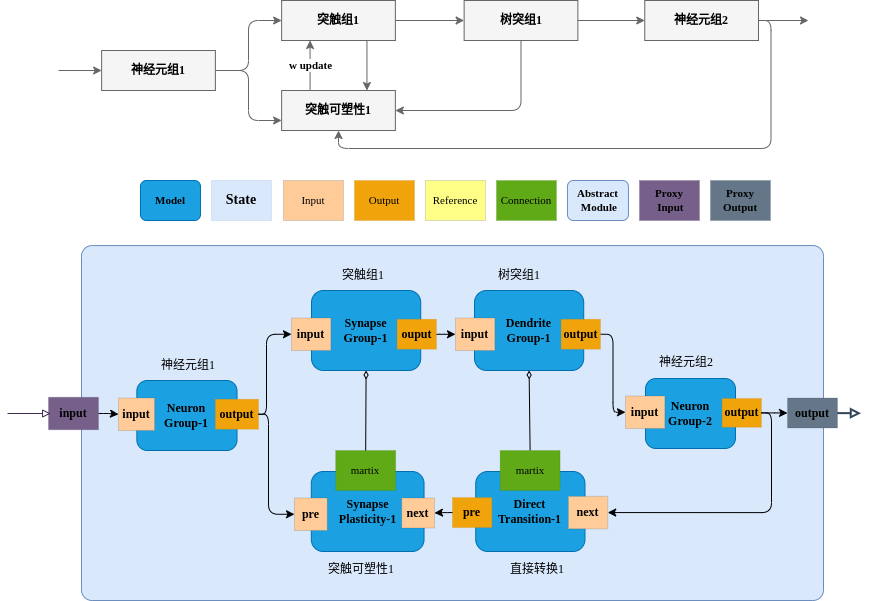
2.6.3 神经元-突触-树突-神经元-突触可塑性
2.6.4 神经元输出增强
2.6.5 神经元输入增强
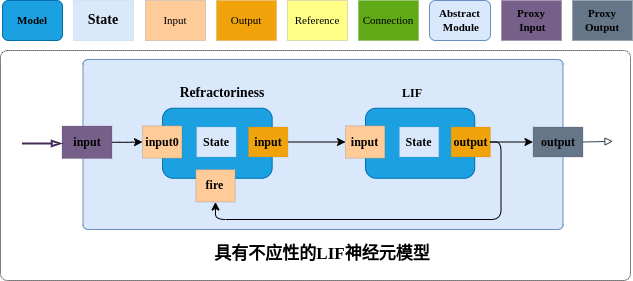
2.6.6 模块嵌套及复用
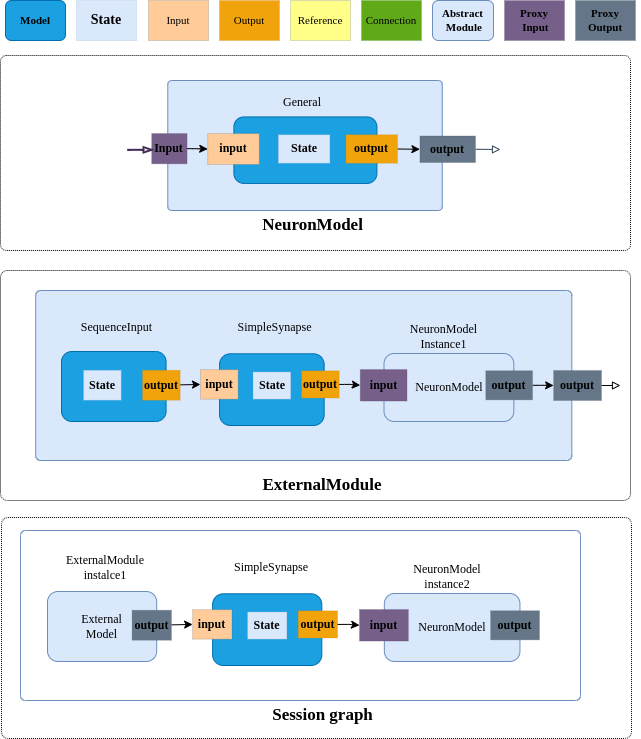
3. 模型运行及监控
Executor负责模型的运行及状态监控。
执行状态比较复杂,包括:
- 初始化
- 编译中
- 编译错误
- 编译完成
- 状态初始化完成
- 运行 Setup
- 运行 before
- 运行 run
- 运行 After
- 运行 teardown
- 运行错误
- 暂停
- 终止
- 运行完成
支持的接口概括:
- 获取状态, 设置或获取线程池线程数;
- 编译模型;
- 添加变量监控,移除变量监控,获取捕获的监控数据等;
- 运行模型,编译后运行, 暂停运行, 继续运行,终止运行等;
编译及运行均需要指定选项
- 编译选项通过CompileOption进行传递,指定了运行的执行后端设备配置信息;
- 运行选项通过RunOption进行传递,报考是否进行性能分析,运行突触可塑性及运行时长等信息;
Neurocean支持对模型中变量的变化监控,可以动态添加需要进行监控的节点变量,自动完成变量的监控, 也可以随时取消相关的变量监控。
- Neurocean提供了参数注册机制,针对变量的监控对操作节点和建模本身是透明的,可以随时按需增加 或取消变量的监控;
- 执行后端针对操作的参数进行捕获,捕获后保存到事先创建的缓存中,在运行中或运行结束后, 可以随时进行缓存变量的查询;
- 在模型的变量监控时,针对神经元模型,在神经元发放时, 分别记录了发放脉冲时候的尖波点位, 同时记录了恢复后的重置电位,保留记录神经元电位变化过程中的所有电位位状态,为神经元的 状态变化分析提供完整的数据支持;
4. 模型保存及加载
模块及会话提供负责网络模型的保存及加载,支持如下操作
- 将指定的网络结构保存到指定的文本文件中;
- 支持将模型保存为二进制格式,并加载回模型。
5. Session机制
Neurocean使用了模块化的模型组织方式,可以按需灵活进行组合嵌套,提高模块的复用性及灵活性。 为了降低用户的使用入门门槛及使用复杂度,我们将相关功能进行了聚集,保证灵活性的同时实现了接口的统一。 会话机制提供了如下功能:
- 会话管理,会话多实例支持,会话按需重置;
- 构建基础模型,并将模型自动加入会话中;
- 构建模块,并将模块自动加入会话中;
- 从会话中移除模型;
- 变量监控;
- 模型编译及运行;
- 模型结构及状态保存;
6. Python接口
为方便用户的使用,平台提供了Python接口支持。
- VariableValue、Tensor、Variable、Filler、SingleVariable、TensorVariable;
- 模型节点体系的支持,Node, Model, ConnectionModel, NeuronGroup, SynapseGroup, DendriteGroup及AbstractModule等;
- Executor、Session等的支持;
- 专门针对参数传递进行优化,使用了Python的键值对传参方式完成不定参数的传递;
- 针对Filler提供了按元组创建、固定值创建、字符串创建等多种灵活的方式;
- 针对张量数据,与py::buffer进行了兼容设计,可以无缝对接满足py::buffer协议的张量库,如经典的numpy库;
- 专门的优化设计,更符合Python用户的使用习惯,更容易与第三方平台融合;
7. Neurocean的工作流程
Neurocean的整体工作流程相对简单,可以简化为如下的流程:
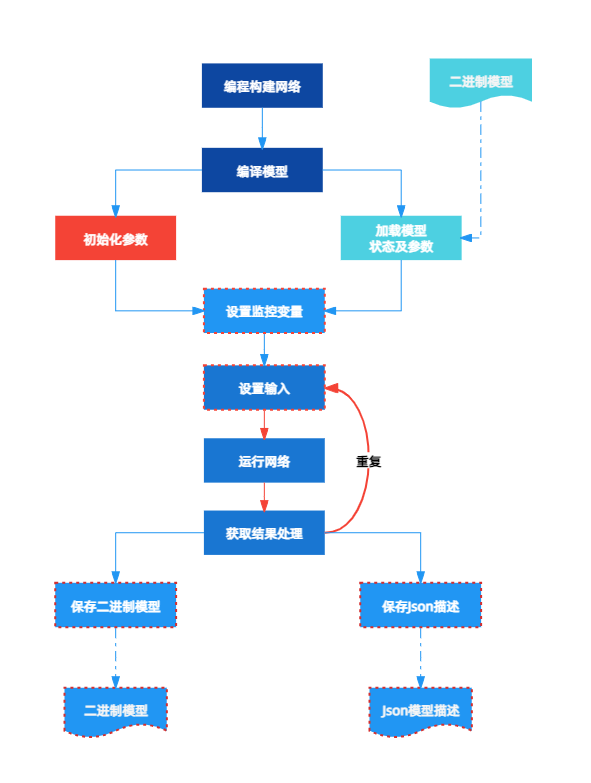
首先是模型的建立,通过编程构建;
编译模型,编译模型的操作比较繁琐,主要是为模型的运行进行准备及优化;
进行参数的初始化或者从参数数据中加载参数,初始化后模型的运行便准备完成了;
设置变量监控,如果有需要监控的变量,需要通过Monitor进行监控,将需要监控的变量添加到Monitor中;
设置输入,如果模型中包含输入节点,需要给模型设置输入;
运行网络,也就是进行仿真;
运行完成,获取结果及监控变量,进行分析或处理。
以上描述了Neurocean使用的大体流程,实际使用过程中是灵活多变的,只要整体满足如上的流程即可,如可以针对5、6、7可无限重复,反复迭代。